As I mentioned on my previous blog – Comet Servers for a Single-Dealer Platform (SDP) I am performing some new benchmarks for Liberator. These are going to focus on some new things as well as some new figures for our traditional scenarios.
Amongst the new benchmarks will be some tests for publishing from the client, which is key for trading applications, and also benchmarking our container objects. A container is an object that represents a dynamic list of references to other data. Subscribing to the container automatically subscribes the client to its contents. Containers also allow you to subscribe to a subset, allowing efficient display of huge lists. The platform allows containers to be created dynamically based on filter and/or sort criteria too.
Anyway, back to the core benchmarks. At Caplin we have never had a customer really need more than the 30,000 client limit Liberator imposed so I never pushed it further than that. When Richard Jones blogged about A Million-user Comet Application with Mochiweb I was intrigued. Richards use case was very different to ours, but I wondered whether Liberator would handle that kind of profile. Later on Migratory published some benchmarks which used our scenarios as a base, but pushed the user numbers higher than we had done.
The hardest part of testing high numbers of users is actually the client side, the machines you need, or tricks you have to make, to get that many connections to your server. I removed the hard coded 30,000 limit from Liberator and set about pushing the user numbers higher.
Deterministic latency can be more important that the absolute value, which is why this new data is so important – Solace Systems talked about Consistent Latency recently. Something I was never happy about with our old benchmarks was they just showed average latency, which is good, but are all messages the same? How much longer do some take? What is the worst case? If you are trading and you get a message that is the worst case latency then that is important to you. So with my latest rig I am measuring min/max latency as well as standard deviation. Both these are represented by error bars on the graph below. Another change is we are now measuring in microseconds and focussing on minimum, but consistent, latency as much as possible.
So here is a taster of the results I am getting. I have pushed it up to 100,000 users. The Liberator is running on a 2x Quad core Opteron box, which was barely breaking sweat, the client machines are what stopped me going past 100,000.
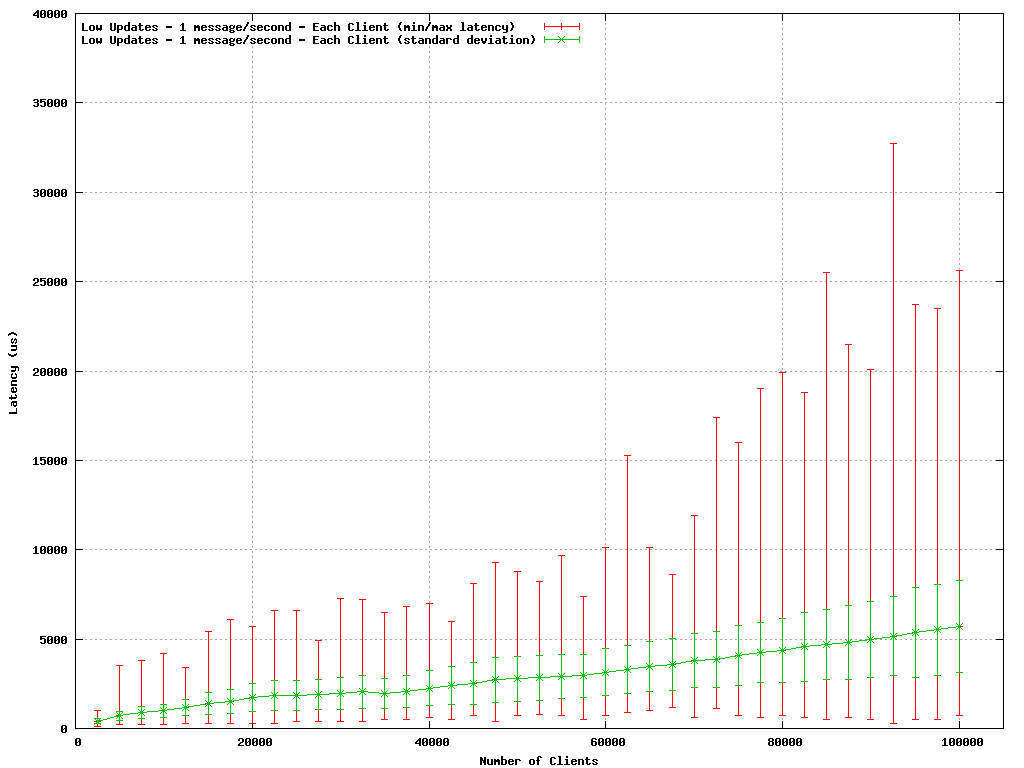
As you can see, the latency is very low. At 100,000 users average latency is still only 6ms. The red max bars show the worst case hits 30ms for one sample, but standard deviation is very small. Each sample ran for 30 seconds, so at 100,000 clients, 3 million messages were measured with the worst being 26ms. If you could zoom in on the start of the graph you would see than 10,000 users can receive 1 message/sec with latency of less than 1ms!
Remember, these are benchmarks, in the real world over the Internet, things will be different – but you have to start with a good base!
I might publish some further graphs as I test the scenarios with higher message rates.