Now that we are building robust internationalisation support into Caplin Trader, there are numerous testing scenarios that can put pressure on the computer running the tests. To avoid corruption, we need proper operating system support, editor support, and to thoroughly test every system that can access the locale files (eg. version control).
So how can we get around the encoding issues and end up with testable locale files?
We have quite a broad base of different operating systems in use at Caplin, most of which are fine. Even Windows XP works well enough after installing some of the optional language support.
Then there are the editors. In addition to various text editors, Eclipse is the IDE of choice at Caplin, and it has a well hidden setting to override the default file encoding (Preferences -> General -> Workspace -> Text file encoding) and work with UTF-8 everywhere. This can also be done on a per-project basis if necessary.
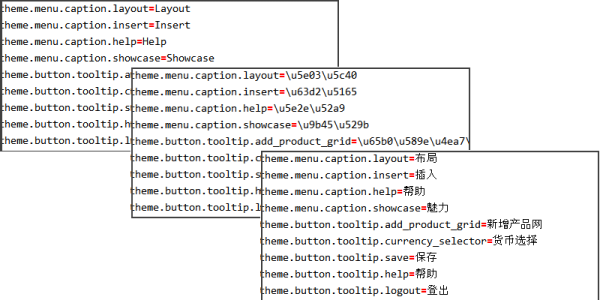
That should be enough to get started. We already had a default locale file, so I used OmegaT to machine translate it into bad Chinese and saved the result. Unfortunately, the new file is full of unicode escape sequences – strings in the form “\uXXXX\uYYYY\uZZZZ”. That can be used but is no good for testing, so I went in search of a simple tool to unescape the text in the file and output the result in UTF-8.
It was surprisingly hard to find a suitable tool online. So much so that I ended up writing my own. First I tried Java because it should work everywhere and has extensive unicode support. After fighting with it for a little while, and only getting encoding problems in the output and no error messages at all, I decided to use something else.
I wrote a quick script in Python to do the conversion and spent some time analysing the errors that occurred when trying to write the output to the console.
After some hair-pulling, I realised that it was trying to output text in the encoding of the calling process, a DOS window (cp850). The DOS, or more properly cmd environment simply doesn’t support asian scripts. It barely even supports English, come to that.
Thankfully, the solution was quite simple. All I had to do was open a file with the desired encoding and write directly to that. The resulting python script to unescape unicode strings is on GitHub.