Caplin Discovery introduces runtime scaling to the Caplin Platform.
Why do we scale?
Ideally we’d be able to scale resources up when demand is high and scale resources down when demand is low. For example, scale down at the weekend when there is no trading, scale up for Monday morning, and then scale up further if there is an alert that demand for resources has increased.
There will always be occasions when we require more resources to service requests in a timely manner. Key examples might include a black swan event like the Swiss currency crash of 2015. However, regular events like monthly payroll figures can also cause spikes in trading.
Ideally it should be easy to quickly scale up or down to ensure that there is sufficient infrastructure bandwidth to accommodate these key events. Traditionally this has been achieved by sizing hardware that is capable of coping with peak events without any interruptions. However, this means spending to accommodate the peak event, and not being able to scale back and save money in between.
Traditional Platform scaling
Traditionally, scaling a Caplin Platform deployment requires downtime to add additional components into a Caplin Platform deployment. That is, it works on the traditional pre-configured deployment model, and peak events would need to be planned for in advance, in the same way that hardware is pre-scaled to cope with peak market events.
Traditional platform scaling can allow an even distribution of load across multiple adapters, so that peak loads are evenly spread across the existing statically scaled resources that are available:

To protect time and investment in capacity planning, Caplin aims for consistency across releases in the performance profiles of Caplin Platform components. All Caplin Platform releases undergo rigorous soak testing, with additional performance benchmarking performed on each major release. The benchmarking ensures that each major version is as performant as the last, and meets our low latency performance characteristics.
Cloud scaling
A key tenet of moving to the cloud is that you only use (and pay for) as much as you need for as long as you need it, in terms of resources. This, however, will only work if the software and applications you use can easily work within this paradigm. That is, if they are “cloud ready”.
We saw above that the traditional approach to coping with peak usage is to scale your hardware to the level of that peak usage from the start. Cloud scaling means only scaling to peak resource usage when it is indicated that you need to do so.
To achieve just-in-time scaling we require two things:
- The ability to dynamically scale on demand, without any interruption to service.
- Monitoring of current usage with clear ‘Service Level Objectives’ that will indicate when resources need to scale.
Scaling Platform with Discovery
Caplin Discovery introduces runtime scaling to the Caplin Platform by removing the requirement to pre-configure component instance numbers and network locations. Instead, components in the Caplin Platform stack connect to Discovery and ‘discover’ their peer components in the stack at runtime.
Discovery orchestration of Platform deployments enables scaling at runtime, with no downtime required to add or remove components instances. For example, it is easy to increase the number of instances of an adapter from 1 to 3 and back down to 1 as required. By using server resources and power only when required, a Discovery deployment saves on hosting costs and helps meet corporate, and possible future regulatory, carbon-neutral goals.
With Discovery, capacity planning focuses more on how and when to trigger scaling, rather than sizing the system for peak loads in advance.
How scaling is implemented depends on the hosting platform. In a VM based deployment, scaling the number of component instances could be achieved with a simple shell script to increase the number of adapters running for a particular service. In a Kubernetes deployment, scaling might be achieved with a kubectl command to add containers for additional Liberators or additional adapters.
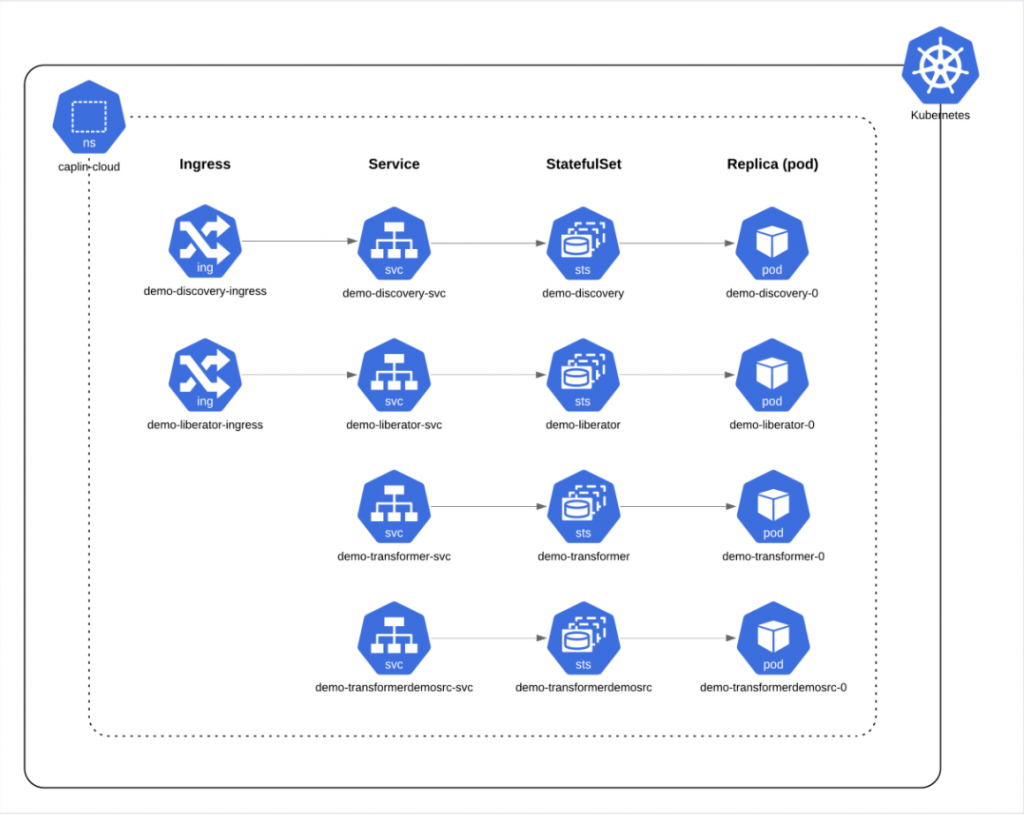
Caplin customers can request access to our example Discovery Kubernetes deployment, which includes examples of scaling components within a Caplin Platform deployment.
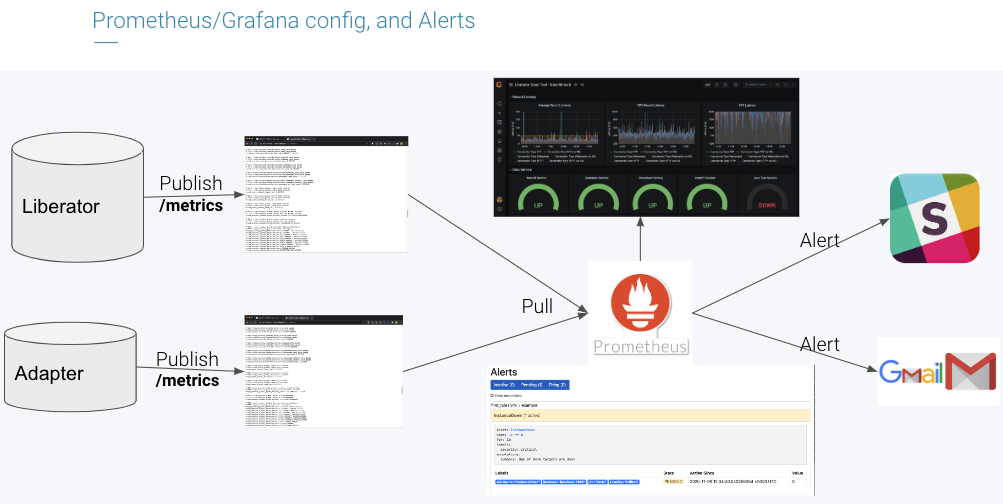
When to scale will be the subject of a future blog post, in which we will provide an example of how to implement Service Level Objectives integrated with industry standard tooling to help maintain the health of deployments, and provide alerting when scaling may be necessary.