Caplin hackdays happen twice a year and are a perfect opportunity to try new things, many of which end up in our products. The theme for our July hackday was ‘Smart Caplin’, and our team SalesIQ wanted to investigate whether we could use machine learning to transform our FX Sales dashboard into a powerful tool that would empower sales dealers with predictive capabilities and a deeper understanding of client behaviour.

Generating a mock dataset
Caplin designs and builds technology components and solutions for our clients, primarily banks, who have full control over their own data. Leading up to the hackday, our first question was how could we train and test models, without access to a large example dataset.
Random data could in theory be quickly generated to run through a training process, but lacking any innate trends would make this process fairly meaningless, and difficult to test a variety of models effectively.
We therefore created a little mock data project that any hackday team could use. To create a meaningful dataset for foreign exchange (FX) transactions, we developed a client specification in JSON that captured various parameters and behaviours representative of real-world trading scenarios. One such client in our mock dataset was Cedric Luck from imaginary company ‘Zatheon’.
Below is the JSON specification for Cedric Luck:
{
/* Trades late in the month and late in the week. All pairs
apart from EURUSD. Medium size deals, mostly sell. Not
particularly margin sensitive. Asks for price only 10% of the
time. */
id: "cedric.luck@zatheon.com",
name: "Cedric Luck",
weeks: [0.2, 0.2, 0.8, 0.8, 0.8],
days: [0.0, 0.0, 0.1, 0.8, 0.8],
pairs: {
EURUSD: 0,
AUDUSD: 0.9,
GBPUSD: 0.9,
ZARUSD: 0.7,
CADUSD: 0.5,
},
amount: {
min: 500000,
max: 1000000,
},
side: {
buy: 0.3,
},
margin_sensitivity: 0.0009,
price_discovery_only: 0.1,
recently_less_active: false,
}
Each property of the object contains data that will be used to seed our mock data with certain trends: ‘weeks’, ‘days’ and ‘pairs’ contain the probability of the client trading on each week of the month, day of the week and currency pair respectively.
We also include information on the minimum and maximum amount that the client will trade, the probability of them selling versus buying, how margin sensitive they are, the probability that when they call they are only interested in finding out where the market is at rather than trading, and whether they have recently been less active.
By incorporating these characteristics into our mock dataset, we aimed to challenge our machine learning models to identify patterns in Cedric’s, and other mock client’s, trading behaviour and predict their future actions. This process allowed us to simulate realistic trends and evaluate the effectiveness of our predictive insights.
Predictive Insights and Daily Trade Predictions
The first insight widget we wanted to try and build, was a component that would highlight to the sales dealer the likelihood of certain clients trading on specific days, or weeks. Through this dedicated widget sales dealers could receive real-time indications of a client’s likelihood to engage in specific trades on any given day.
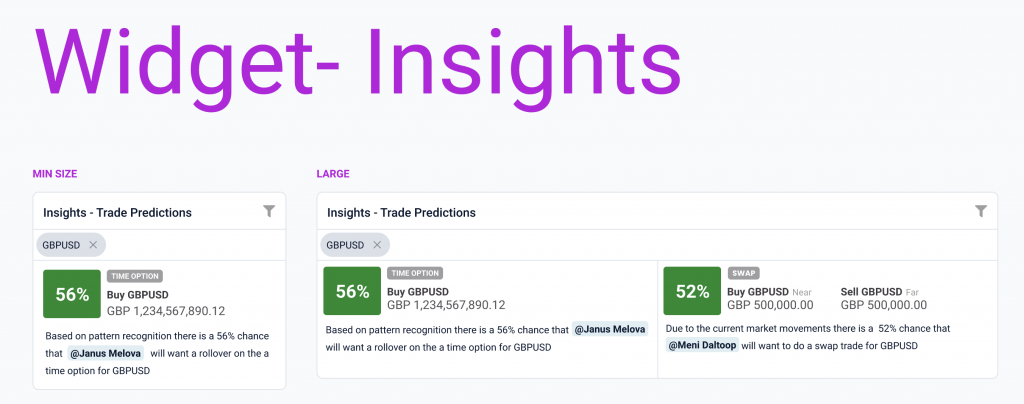
Often an FX sales team can have many thousands of clients they are working with, so it is difficult to always know who would be best to reach out to on any given day with information that may be relevant to them. An example could be an expected upcoming market move that might mean the client should hold off on a trade that they would otherwise typically perform that week. A widget like this could help sales dealers to provide more value to their clients, by using their limited time most effectively.
Partnering with TurinTech
In our quest to develop the widget and machine learning model that would power it, we sought the expertise of the TurinTech team, a provider of machine learning software to aid with the training, development and testing of custom models. The evoML tool allowed us to quickly ingest our mock data, train and test various models, and output a working model to use for our predictions.

Overcoming Data Challenges
During the development of SalesIQ, we realised our mock data wasn’t quite in the right format to drive the prediction we were trying to achieve. By collaborating with the team at TurinTech, we were able to address these challenges by transforming the table of trades, into a table of every day since the start of our dataset, and whether a client traded or not. Having these positive and negative entries in the dataset was key to then being able to train the model.
The Training Process
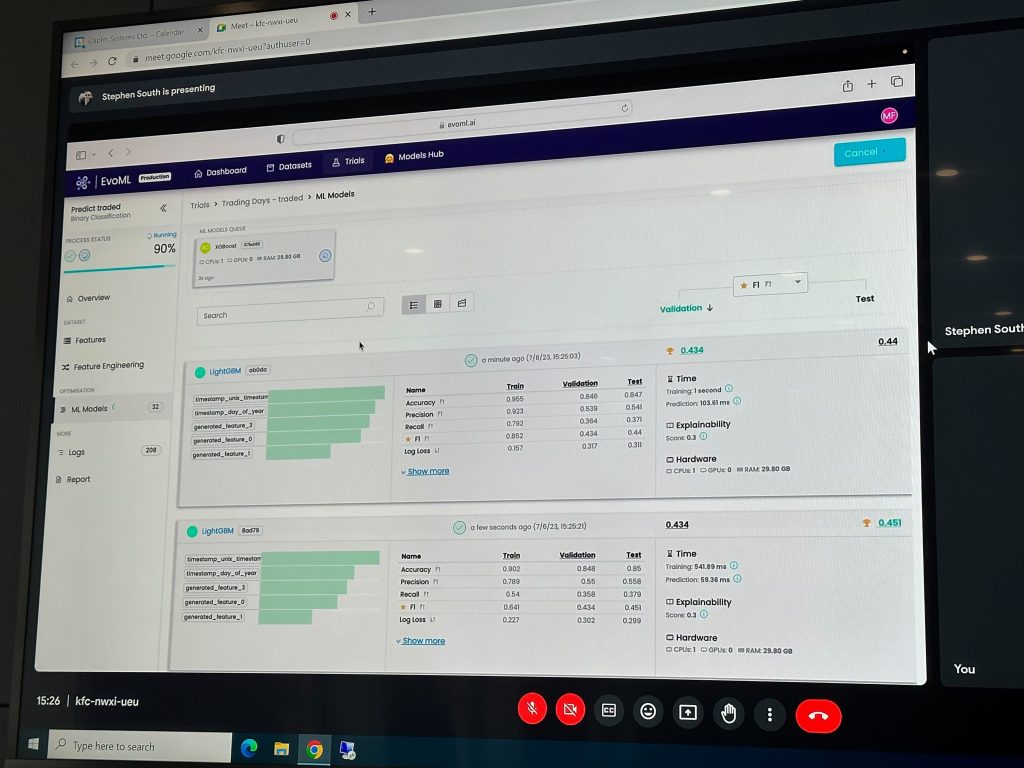
Once we had the dataset in the right format, we used evoML to train and test a variety of models. The best performing model, with no additional parameter tweaking, was XGBoost.
“XGBoost, which stands for Extreme Gradient Boosting, is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. It provides parallel tree boosting and is the leading machine learning library for regression, classification, and ranking problems.” nvidia.com
Once we had our chosen model, evoML generated the code and api we could then consume as part of our hackday demo.
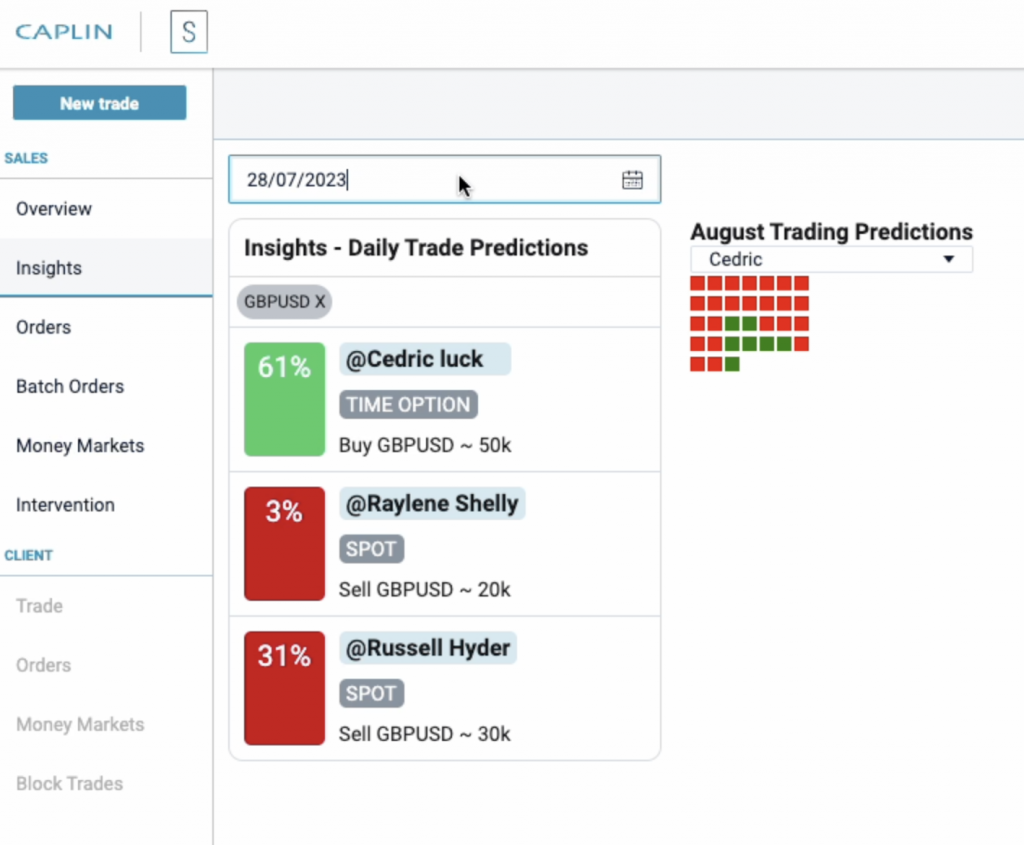
The Final Widget
By the end of the day we had a working widget in FX Sales, which called our XGBoost model to highlight the likelihood of a client trading. It is possible to see from this example that the model is doing a good job of uncovering the pattern in the data that we seeded it with, i.e. that cedric typically trades towards the end of the week and end of the month.
While our predictive model was trained on simulated data, this use case demonstrated a practical approach to exploring machine learning with limited resources:
- Generating mock data representing real-world parameters allows testing models when real data is inaccessible
- Leveraging tools like evoML speeds up model building/testing to uncover the best performer
- Translating raw predictions into a simple interactive interface makes insights actionable for the sales team
- Starting with a limited prototype generates learnings to inform future iteration and expansion
The process we walked through can serve as a blueprint for our teams when looking to harness predictive analytics:
- Identify available data sources, or create mock data
- Explore different ML algorithms
- Integrate top model into application and translate outputs
- Gather feedback, monitor impact, and improve over time
While an oversimplified example, this hackathon process enabled our team to gain hands-on experience with machine learning in a compressed timeframe. We’re excited to apply these learnings on future projects to empower our clients and their users with data-driven insights.
The SalesIQ Team
Stephen Seager, Finn Holt, Steve South