Last month Emin Tatosian posted an article about agile team-board layouts in which he showcases one of our more successful board designs. It’s fair to say that we don’t always get it right first time, so I thought I’d share an example of a layout that seemed to be a good idea at first but turned out to be badly flawed.
A few sprints ago I moved to a team in charge of maintaining our existing products and reducing technical debt. We had a backlog of low priority bug fixes and enhancements to work through and no specific client deadlines, so as team lead I thought this would be a good opportunity to try out the kanban methodology. After a bit of consideration the team came up with this board layout:
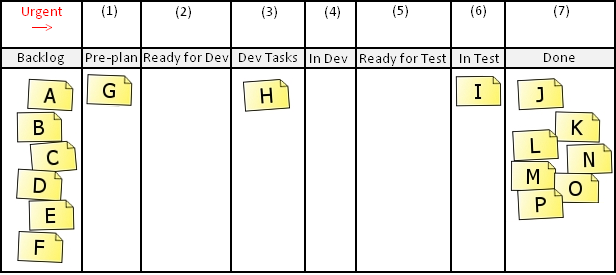
We thought that the workflow for any given story would be along these lines:
- A developer or pair of developers picks the top story card from the backlog and moves it to column 1. We use the power of three concept for pre-planning, so at this point the developer will go and grab the product owner and a QA engineer to have a quick chat about what the task involves. The acceptance criteria will be determined at this point. The card is then moved to column 2.
- Any free developer can pick up the card from column 2 and move it to column 3 to start work on it. At this point the developer should break the story down into tasks and place the task cards in column 4 as he works on them.
- When the developer is finished with the story he will get a QA engineer (ideally the one involved in the pre-planning stage) for a quick “show me”, to demonstrate the fix. The card then moves to column 5.
- A free QA engineer will pick up the card from column 5 and move it to column 6, then test the change thoroughly. This involves verifying the fix in every browser that we support, attempting to find edge cases, checking that sufficient automated tests have been written and so on.
- When the QA engineer is satisfied, the card moves to column 7 and is done.
That’s what we thought would happen, and we were fairly confident that the board matched our actual workflow. However when we put it into practice we quickly discovered that the adage about no battle plan surviving first contact with the enemy was coming true – cards were bunny hopping across the board with scant regard for several of the columns:
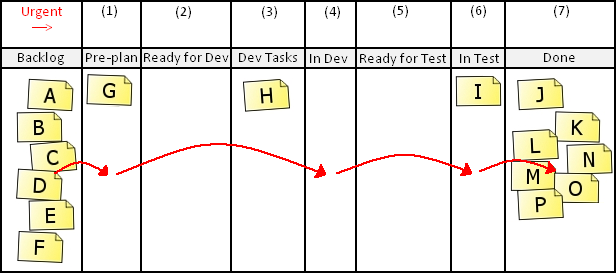
It was soon fairly obvious why this was happening.
- After the pre-planning stage (column 1) the developer would always begin work on the task immediately and move it directly to column 3 – it would be very odd for a developer to gather up the relevant people for a planning session and then leave the card in column 2, going off to work on something else. Column 2 is therefore completely redundant.
- Most of our stories were fairly trivial bug fixes which resisted our attempts to break them down into sub-tasks. This meant that in practice the entire story card would just be moved straight into column 4, skipping column 3 completely. This probably indicates that our stories were too small – it would have made more sense for a story to take the form “Fix 5 bugs in product X”, which can naturally be split into sub-tasks.
- After the “show me” session the QA engineer would almost always take on the testing straight away, moving the card straight from column 4 to column 6. Cards very rarely paused along the way in column 5.
Needless to say, this all came out during our first sprint retrospective and our kanban boards have evolved since that first attempt. But it taught me something – you might think that you can draw out your workflow with your eyes closed, but how closely does your theory match reality?
That’s what I love about the Kanban system it exposes how you are REALLY working and therefore makes everyone aware of the issues rather than carrying on with blissful ignorance.
mmm maybe we should try taking kanban boards into a contextual study and map the workflow onto it… The rationale behind contextual studies is that people can’t ‘tell’ you what they do, as a lot of the time the steps are done without having to think about them.
It’s not so much working with your eyes closed, more… that as you become ‘expert’ you enter a work ‘flow’ state and can work without having to think about HOW you are doing, but concentrate on WHAT you are doing.
Out of interest, did you have WiP limits for each column?
Hi Joshua,
Adam isn’t in the office at the moment, however I believe that I can answer your question. The team didn’t have any WiP limits, although we have used them previously. The reason that we didn’t was because we were trying to determine where our natural bottlenecks were, which would then allow us to work out what the limits should be in the future. This was based on a suggestion from David Anderson after a conversation one of my colleagues had with him about Kanban at a conference.
Yep, I had the chat with David Anderson (Thought Leader of Kanban Systems) and I asked the question about Joseph Pelrine statement of creating an environment for teams to become self-organising, Pelrine states that you need to “turn-up the heat” within the team (not quite chaos but close) to see the team burst into energy and start self-organising, with scrum this is achieved by the timebox cycles. His presentation can be found here http://www.infoq.com/presentations/coaching-self-org-teams. So I asked the question to David Anderson how this is achieved with Kanban because Kanban leads to a calm steady flow through the system. He said use WIP limits to have the same affect of “turning up the heat” but if you are new to Kanban start working without these to map how you are currently working before making lean changes through WIP limits.
This was at SkillsMatter Lean and Kanban eXchange last December http://skillsmatter.com/event/agile-scrum/lean-kanban-exchange
so wouldn’t a ‘pure’ kanban board just be not started, in progress, and done? Don’t take this offensively, i just want to know: what’s the purpose of the other columns? When would you actually use them?
That would only work if you only have one ‘kind’ of resource, eg developers.. if you have developers and testers and whoever else you need states between these parts of the process
There is an interesting point concerning “User Stories” / “Simple Bugfixes”. Our team uses redmine (ticket system with configurable workflow) intensively. We have made the experience that every artifact from big chunks like ideas or user stories to fine-grain tasks like small feature requests or bug fixes is wrapped in a ticket and treated in the same way. Maybe this is wrong. It might make sense to treat them in a different way, with different workflows, maybe even in different systems…
Yes, we struggled a bit with this because if the tasks going through the kanban board are not relatively similar in size it reduces the value of the metrics you get out of it. We might, for example, have a simple one line change to some documentation and a hefty 10 day user story going through the same board. In that case is the estimated transit time per task actually useful?
One approach we tried to mitigate this problem was to package up simple changes into baskets of changes, so that if a quick update had to be made to a document then the developer would also look for other fixes/enhancement requests for that document in order to bulk up the task. That had the benefit of making our tasks more consistent in size, increasing the accuracy of the metrics, but with the trade off that developers were spending time working on tasks that, strictly speaking, didn’t need to be done at that point. Which isn’t ideal!
It’s definitely an interesting problem and I’d be interested to hear other approaches to deal with it.
I know this post is a couple of years old already. The issue related to the size of work items making cycle time metric less valuable. Would it not help and does any one have experience doing this, estimating story points and determining cycle time per story point?
Hi Brand,
It’s an interesting idea and I think something like that is definitely a useful metric for more of a project-based team rather than a maintenance team. As I recall we were trying to keep our process on this team as lightweight as possible due to the nature of the work, which was primarily to pull bugs and maintenance tasks from a queue that could be populated by multiple other teams and keep the fixes flowing smoothly through to completion.
Most of the bugs had descriptions that fully described the problem, which meant that we spent very little time doing estimation. Our first column (pre-planning) wasn’t used very much.
Nice article, although I’m confused about how you use the terms “story” and “task” interchangeably.
Isn’t a task the requisite components that make up a “user story” (or “feature”)? And therefore, shouldn’t it be the tasks the flow through the board rather than an entire story?
For example, a particular story/feature might involve a design task, front-end mark up and back-end DB change. So wouldn’t it be easier if these were split out as tasks and can each be developed in parallel?