SuperSelector is a lightweight JavaScript GUI tool to help you generate ‘smart’ CSS selectors by simply Ctrl + Clicking anywhere on a web page.
What makes it cool?
- Easy to use – Ctrl + Click!
- Very accessible (available as a bookmarklet to add to your bookmark bar)
- Highly configurable – manually and programmatically
- Always returns a correct result
The problem
Testing through the browser DOM is difficult. Automated browser tests which interact with the DOM require you to have a (reliable) way to identify all the elements on the page that you care about.
The problem is that this form of testing is ‘flaky’ by definition, as you are testing further up the testing pyramid.
The higher up the pyramid we test, the more expensive and unreliable our tests become.
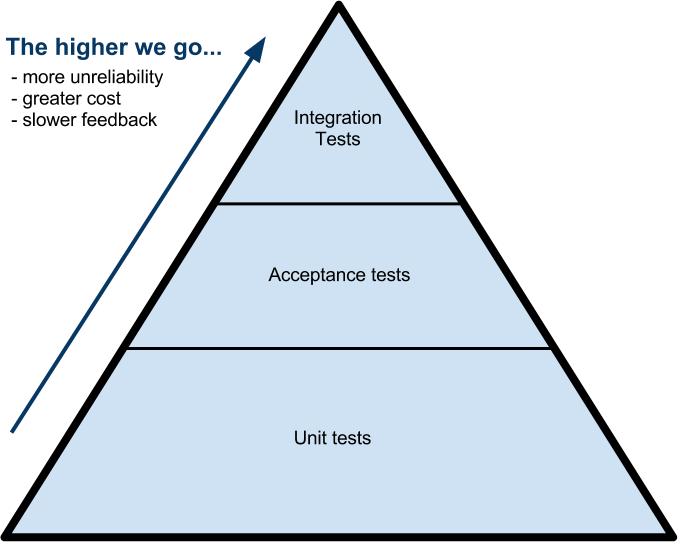
It is unrealistic to expect the HTML of a website or a web application to have ID values for each of the handles your test may need. Having better element selectors in your tests can save you hours of time in test maintenance.
In web development and in this particular type of browser testing, a large amount of time often goes into querying DOM elements via the browser console and then translating that into test code or analyzing a test failure and then trying to run the same selector manually to get more information.
The time spent on these activities add up.
Use class names and IDs, XPaths are bad
Class names and IDs help our selectors in our test code be more readable (whether it’s in JavaScript or in Java using WebDriver).
XPaths should be avoided at all costs as they are the most brittle means to identify web elements.
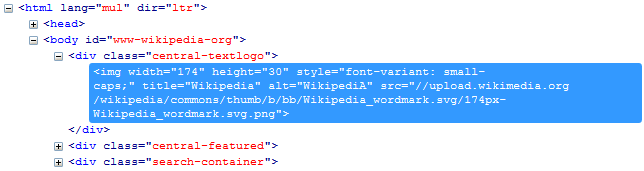
Example: The wikipedia text logo element found on www.wikipedia.org
- XPath Selector: /html/body/div/img
- CSS Selector: document.querySelectorAll(“.central-textlogo img”);
One of the biggest motivations behind SuperSelector is to encourage better use of selectors in browser testing.
Where ‘better’ is defined by reliability and readability.
From the example above, the CSS selector is far more meaningful to me than the XPath selector. If somewhere down the line a parent div element was added, the XPath selector would break, but the CSS selector would still work.
An example using SuperSelector
- Go to a web page or web application
- Launch the SuperSelector bookmarklet from your browser toolbar
- Ctrl + Click on the wikipedia text logo element
- Styling applied to the target element and the selector is generated
Who would use SuperSelector?
Any developer/QA working on automated tests which involve the DOM:
- Selenium/WebDriver tests
- UX / Web Designers who are interesting in styling a webpage/app
- Anyone looking to teach someone about how CSS selectors work and understanding the DOM tree
How does it work?
A quick high-level overview on the algorithm:
- The target element is captured on the Ctrl + Click
- SuperSelector traverses up the DOM tree querying both the current location’s parent element and the global document (DOM)
- We’re interested to see if the target element has an ID
- Whether it has a class/tag which is unique to the global document
- Whether it has a class/tag which is unique to it’s parent
- Fall back to using ‘nth-child’ selector as a last resort
- etc.
- Continue to build up a selector string until we find one which is able to return the original target element
- Return this to the user
This is exactly what I was looking for, thanks!!
So this doesn’t work on Mac because ctrl+click is like a right-click.
Firstly, thanks for your interest! I haven’t had much time to improve on it as I’d like but I’ve put in a quick patch which should hopefully allow Mac users to use it through ‘cmd + click’ in the mean time.
For MAC : use command + click
An awesome tool for those looking to automate their test cases using any automation tool.
– Excellent article, thank you very much for sharing the experience and for the tool !
A. Whenever the tool is not triggered on a certain webpage (for unknown reason), the specific webpage I save it offline
B. Open the offline webpage and then use the “Superselector”
the tool fail to intialize for example in an https page : )). These page could be saved offline and the tool triggered
Cheers
How do I install your tool? I dragged your link to my bookmark bar in Chrome and clicked on it but nothing happened…
does not work on gmail ,googleplus